Après toutes ces observations sur l’héritage des classes, le lecteur se demande peut-être « comment ça marche » . Il n’est pas nécessaire de le savoir en pratique (il suffit de savoir que ça marche en effet), mais cela peut être utile à l’occasion. Nous expliquons ci-après comment Turbo C++ implante les classes (il peut y avoir des variations selon les compilateurs) ; pourquoi les instances de classes contenant des méthodes virtuelles prennent deux octets de mémoire de plus que les autres ; pourquoi certaines opérations sont impossibles.
Prenons d’abord le cas simple suivant :
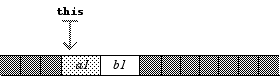
class A { int a1; public : // ... méthodes };class B : A { int b1; public : // ... méthodes }; La configuration en mémoire d’une instance de B est alors la suivante (chaque petit carré représente un octet) :
La partie grisclair représente ce qui est hérité de la classe A, tandis que la partie blanche indique ce qui est défini directement dans B.
Si une méthode de A est appelée, elle reçoit comme les autres l’adresse de l’objet par l’intermédiaire du pointeur this. Or, vu l’ordre dans lequel les champs sont placés, ce pointeur indique en mémoire la partie « instance de A » de l’objet ; de ce fait, les méthodes de A fonctionnent exactement de la même façon sur une instance de A ou de B, et n’utilisent dans ce dernier cas que la partie gris clair.
Compliquons un peu les choses en supposant que B a des méthodes virtuelles :
class B : A { int b1; public : virtual void b2(); virtual void b3(); void b4(); }; Dans ce cas, les instances de B sont représentées différemment en mémoire :
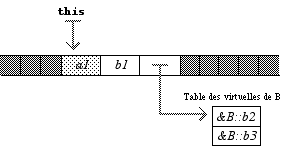
Chaque instance contient à présent un pointeur caché sur une table fixe (il en existe une seule pour toute la classe B) qui contient les adresses des méthodes virtuelles. Lorsque le compilateur rencontre un appel à b2 par exemple, il regarde ce pointeur caché dans this (ou dans l’objet qui appelle b2), puis l’augmente d’autant que nécessaire (ici 0) pour être sur la bonne méthode ; ayant ainsi l’adresse de la méthode, il ne reste plus qu’à y sauter.
Ce processus s’appelle lien dynamique ou lien tardif (en anglais late binding). On notera que les méthodes non virtuelles en sont exclues (b4).
Nous allons voir comment cela fonctionne plus exactement en imaginant une nouvelle classe :
class C : B { int c1; public : void b2(); void b3(); virtual void c2(); }; Cette classe recouvre les deux méthodes virtuelles de B. Une instance de C a l’allure suivante :
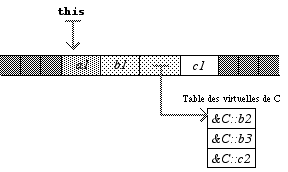
Le pointeur caché n’a maintenant plus la même valeur que dans les instances de B : il pointe sur une nouvelle table particulière à C, et dans laquelle les adresses des méthodes recouvertes figurent à la place de celles de B. Lorsque le compilateur rencontrera un appel à b2 avec une instance de C, il ira chercher dans cette table-ci (sans le savoir, car il exécute exactement le même travail qu’avant), et passera donc dans la bonne méthode recouverte C::b2. Ceci explique le fonctionnement des méthodes virtuelles : le pointeur caché est identique pour deux instances d’une même classe, mais différent pour deux classes distinctes ; de ce fait, il caractérise la classe à laquelle appartient l’instance, et permet donc de choisir la bonne méthode.
Compliquons encore le jeu avec un héritage multiple :
class D : B { int d1; public : virtual void d2(); void b3(); };class E : D, C { int e1; public : void b3(); void c2(); }; L’allure d’une instance de D est la suivante :
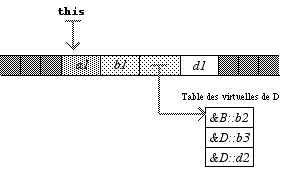
On remarque que, comme la classe D n’a pas recouvert la méthode virtuelle b2, c’est l’adresse de B::b2 qui figure en première place dans la table.
Jusqu’à présent nous n’avons augmenté la taille des objets que de deux octets au maximum. Il n’en est plus de même avec l’héritage multiple. Voici l’allure en mémoire d’une instance de E :
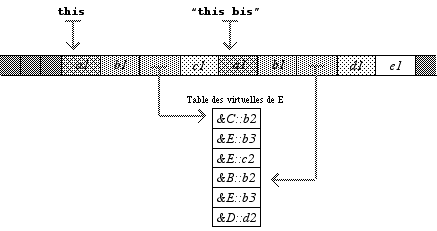
Dans ce cas, il y a deux pointeurs cachés, dans chacune des deux instances de base C et D contenues dans E. Les tables sur lesquelles ils pointent sont semblables à ce qu’elles étaient dans C et D, sauf que les méthodes recouvertes de E y remplacent celles de C ou D. On notera que la méthode E::b3 figure deux fois dans la table de E, parce qu’elle recouvre à la fois C::b3 et D::b3.
Lorsqu’on appelle une méthode de D avec une instance de E, ce n’est pas le pointeur this qui est passé, mais celui que nous avons nommé « this bis » , qui correspond au début de D en mémoire.
Lorsqu’on utilise un héritage virtuel, la situation est beaucoup plus complexe. Supposons que les classes C et D aient été déclarées en héritage virtuel de B :
class C : virtual B { ... } class D : virtual B { ... } Dans ce cas, l’allure d’une instance de C en mémoire est bien différente :
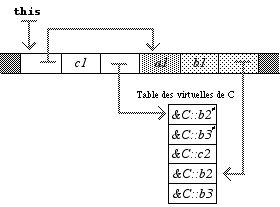
Trois pointeurs sont ajoutés ; le premier, en tête, indique l’emplacement dans l’instance du début de la partie héritée de B (cet emplacement variera dans les classes dérivées de C). À la fin de l’objet, un pointeur désigne une table formellement identique à celle de B, mais avec les adresses des méthodes virtuelles recouvertes. Au milieu, un troisième pointeur donne les adresses des méthodes virtuelles de C (dans l’ordre de déclaration) ; les méthodes b2 et b3 sont ici remplacées par b2* et b3*, qui sont identiques à ceci près qu’un petit bout de code avant fait remplacer this par le pointeur de tête, afin que les méthodes aient la bonne adresse.
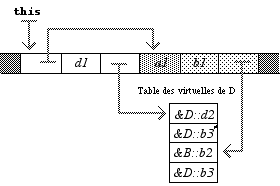
L’allure de D est assez semblable, sauf que b2, qui n’est pas recouverte dans D, n’apparaît pas dans la première table :
On a à présent ceci dans E :
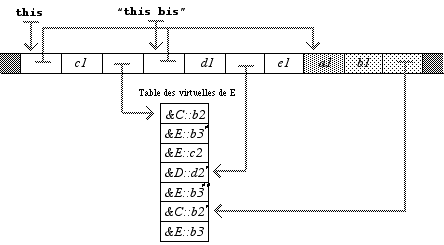
La partie initiale correspond à C ; elle comprend le pointeur de tête sur la base héritée de B, le champ c1 et un pointeur sur les trois méthodes virtuelles de C, toutes trois recouvertes dans E ; notons que la partie B de C n’existe plus (pas de duplication). La suite correspond à D : on trouve le pointeur de tête sur la partie B, le champ d1 et un pointeur sur les deux méthodes virtuelles de D, dont une recouverte dans E (b3). Vient ensuite le nouveau champ e1 ; puis enfin la partie héritée de B, en un seul exemplaire, avec à la fin un pointeur sur les méthodes virtuelles de B, toutes deux modifiées dans E (une directement par E, l’autre indirectement par C). Tout cela est compliqué par le fait que les méthodes doivent être augmentées de petits bouts de code destinés à récupérer la bonne adresse de this. L’adresse « this bis » est celle qui est utilisée pour les méthodes de D.
On retiendra surtout qu’il s’agit d’un processus complexe, dans lequel il est préférable de ne pas intervenir, et que la taille des objets est difficile à prévoir (utiliser l’opérateur sizeof pour la connaître).
| Suivant |